AI coding agents are making us worse engineers, unless we add discipline back. Here is what we do instead of vibe coding, and how you can do it too in 30 seconds.
Update, May 2026: this repository is now private
Up until last week, terraphim-skills was open source. You could install the whole set with one command via skills.sh. Then I ran a comparison: our skills against Andrej Karpathy's, against derivatives of Karpathy's, and against a no-skills control. For the first time in my life I clicked "Make private" on a public repository.
Even on the first batch of tests, our approach beat both Karpathy's and the control:
- 85% traceability of code back to the original requirements
- Tests written by default, not bolted on after the fact
- No ralph loop, no autoresearch swarm, no token-burning
We control the flow and we control the cost, because we are not an AI lab and we are not a VC-funded startup burning tokens to chase a leaderboard. We are a consultancy getting things done with AI and building AI.
The results speak for themselves. A few weeks ago I read a story about an autoresearch agent that achieved a speedup on the Liquid (Rails) parser. I had a slow markdown parser inside this very project. I ran our disciplined loop on it. Twice. Result: a 400x to 900x speedup in parsing.
Here is how.
The Vibe Coding Problem
Every AI-generated pull request we review has the same pattern:
- Scope creep beyond the original task. You ask for a bug fix, you get a refactored module.
- No traceability from requirements to tests. The agent shipped code, but nobody verified it does what was actually asked.
- Knowledge lost between sessions. Each conversation starts from scratch. Yesterday's design decisions evaporate overnight.
The agent shipped code. It even passed the tests. But the tests were written by the same agent that wrote the code, optimising for the metric rather than understanding the problem.
The missing piece is not better models. It is engineering discipline. AI agents need the same rigour humans use: understand the problem before coding, verify against the design, validate against requirements. We encoded this as executable skills that any AI coding agent can follow.
The research evidence behind this framework, including language-specific scaling laws and the 30% adoption gap between code intelligence research and production harnesses, is the subject of our next article.
The V-Model: Adding Discipline Back
We built a V-model for AI agents. The left side asks "what should we build?" The right side asks "did we build it correctly?"
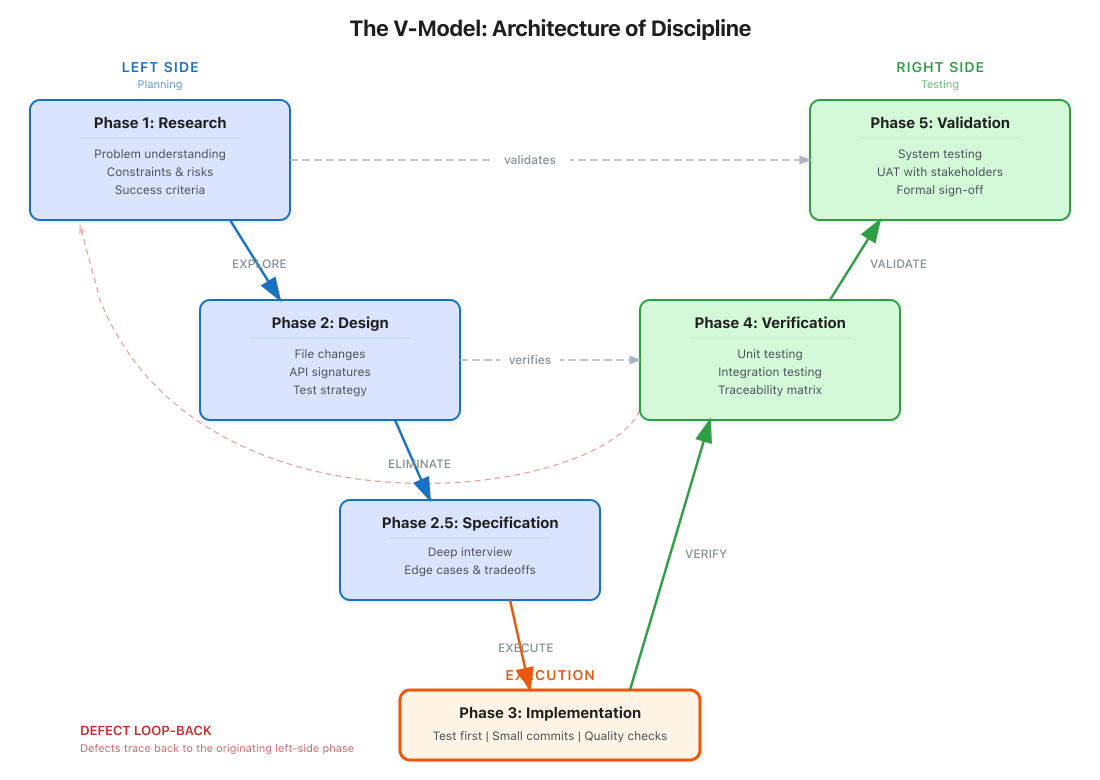
Phase 1: Research
Before writing any code, the agent must understand the problem space:
- Search existing knowledge graphs for relevant patterns
- Identify language-specific constraints
- Determine optimal context window for target language
- Find similar implementations in the codebase
Phase 2: Design
Create a specification before implementation:
- Define interfaces and data structures
- Identify cross-language considerations
- Plan for compiler feedback integration
- Document the "why" not just the "what"
Phase 3: Implementation
Write code with tests from the start:
- Language-appropriate context management
- Compiler feedback integration points
- Type-safe by default (for typed languages)
- Self-documenting through clear structure
Phase 4: Verification
Verify against the design, not just tests:
- Type-checking passes
- Linting passes
- Compiler warnings addressed
- Design intent preserved
Phase 5: Validation
Validate against the original requirements:
- Does it solve the actual problem?
- Are there simpler alternatives?
- What's the maintenance burden?
terraphim-skills: 32+ Executable Disciplines
We packaged the V-model as executable skills for any AI coding agent. As of May 2026 the repository is private (see the update at the top of this post) and the skills.sh installer has been retired. The framework is now deployed as part of our consulting engagements at zestic.ai.
The skills enforce:
- disciplined-research: Understand before building
- disciplined-design: Plan before coding
- disciplined-implementation: Build with tests
- disciplined-verification: Verify against design
- disciplined-validation: Validate against requirements
Each skill is a self-contained prompt that guides the agent through the phase's inputs, outputs, and quality gates.
Quality Gates: The Judge System
Our judge system (Kimi K2.5) catches what humans miss:
- 90% verdict agreement with human reviewers
- 62.5% NO-GO detection rate on genuinely flawed code
- ~9s average review latency
Automated quality gates, zero manual overhead. Every PR reviewed before it merges.
Guard Rails in Practice
AI agents do not type commands into a terminal. They invoke tools programmatically, and they do not always get it right. "Cleaning up build artefacts" becomes rm -rf ./src (one-character typo). "Resetting to last commit" becomes git reset --hard (uncommitted work gone). You need a safety net that operates between the agent and your shell.
We use two layers of guard rails:
Layer 1: git-safety-guard (a terraphim-skill that runs as a PreToolUse hook):
- Blocks
git reset --hard,git push --force,rm -rfand similar destructive commands before they execute - Checks for secrets in diffs before commits
- Validates commit message format
- Zero configuration: install the skill, protection is immediate
**Layer 2: Destructive Command Guard (DCG) by Jeff Emanuel, integrated via tool hooks:
- A Rust binary using SIMD-accelerated pattern matching
- Intercepts every shell command the agent attempts to run
- Returns allow/block verdicts in under 1ms
- Works with Claude Code, OpenCode, and any agent that exposes a pre-execution hook
The architecture is simple: the agent calls a bash tool, the hook pipes the command to DCG as JSON, DCG pattern-matches against known destructive commands, and blocks execution before damage occurs. The agent receives an error explaining why, and can adjust its approach.
Real Example: AI Dark Factory
We run 12+ AI agents overnight on a single machine, coordinated by a Rust orchestrator. Each agent follows the V-model:
- Safety agents run continuously with automatic restart and cooldown. They handle monitoring, log analysis, and drift detection. If one crashes, the orchestrator waits 15 minutes before restarting (up to 3 times) to prevent crash loops.
- Core agents are scheduled via cron. They pick the highest-priority unblocked issue from the Gitea board (ranked by PageRank across the dependency graph), claim it, branch, implement with tests, and open a pull request.
- Growth agents run on demand for research, code review, and content generation.
Every agent's output passes through the judge system before merge. The morning routine is reviewing verdicts, not debugging overnight chaos. When an agent produces a NO-GO verdict, the PR is flagged with the specific issues: missing test coverage, undocumented API changes, or security concerns.
This is disciplined engineering at scale: not process overhead, but automated quality gates that catch problems before they compound.
Conclusion
The gap between what AI agents can do and what they should do is real. It is not a technology gap: it is a discipline gap. The V-model and the 32+ executable skills we built are now part of our consulting work rather than an open repository.
Add discipline back. If you want it inside your team, get in touch at zestic.ai.
Deeper dive: The V-model and quality gates we use are detailed in Chapters 3-4 of "Context Engineering with Knowledge Graphs". Coming soon.
Related posts: